はじめに¶
システムのログ件数やアクセス数は,通常は一定のレートで発生しますが, 障害により,短時間に急増(バースト)することがあります. このようなバーストを統計的に検出することで,システム異常の早期発見が可能になります.
ポアソン分布(Poisson distribution) を使った確率的な異常検知手法を用いて,ログの件数が増えたコンテナ名を特定します.
中央値のかわりに,ポアソン分布
ポアソン分布ってなに?¶
ポアソン分布は,「1分あたりに起きる回数」がランダムな現象を表す考え方です.
たとえば: - 1分に50件くらいログが出るけど,実際には49件だったり52件 → こうした“ばらつき”を説明するのがポアソン分布です.
この分布を使うと「94件も出るのはどれくらい珍しいことか?」を確率で表せます.
珍しさでおかしいか(異常)を判断する¶
ふつう(平均50件)だと,90件以上が出る確率はとても小さいです. つまり「めったに起きないこと」が起きたということになります.
たとえば:
- 50件前後なら「いつもの範囲」
- 60〜70件なら「ちょっと多いけどまだ普通」
- 90件以上なら「1万回に1回あるかどうか」くらいの珍しさ
このようにして「偶然ではなさそう」と言えるときにバーストと判断します.
実際のデータで考える¶
以下は,1分ごとのログ件数の例です.
14:29〜14:42までは平常状態(約50件/分)ですが,
14:43以降に明らかな増加が発生しています.
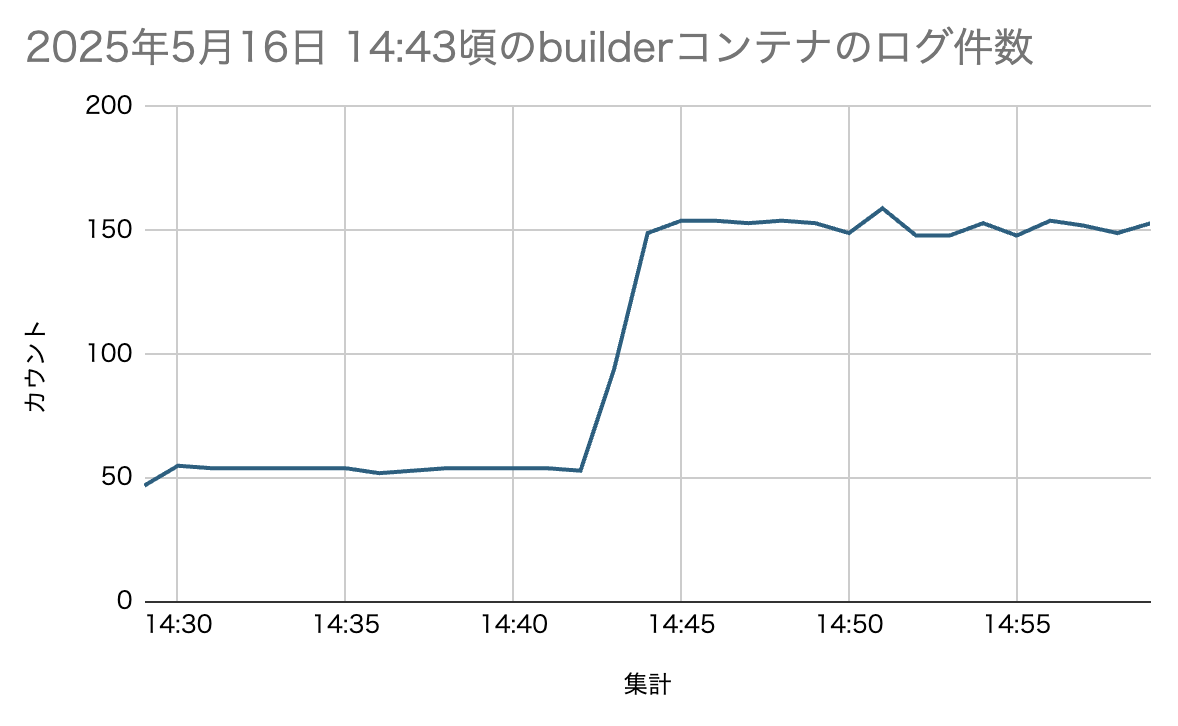
| 集計 | カウント |
|---|---|
| 14:59 | 153 |
| 14:58 | 149 |
| 14:57 | 152 |
| 14:56 | 154 |
| 14:55 | 148 |
| 14:54 | 153 |
| 14:53 | 148 |
| 14:52 | 148 |
| 14:51 | 159 |
| 14:50 | 149 |
| 14:49 | 153 |
| 14:48 | 154 |
| 14:47 | 153 |
| 14:46 | 154 |
| 14:45 | 154 |
| 14:44 | 149 |
| 14:43 | 94 |
| 14:42 | 53 |
| 14:41 | 54 |
| 14:40 | 54 |
| 14:39 | 54 |
| 14:38 | 54 |
| 14:37 | 53 |
| 14:36 | 52 |
| 14:35 | 54 |
| 14:34 | 54 |
| 14:33 | 54 |
| 14:32 | 54 |
| 14:31 | 54 |
| 14:30 | 55 |
| 14:29 | 47 |
このデータでは,14:43から急に件数が増えています.
これがバーストです.
計算手順¶
1. 平常時の平均(λ₀)を求める¶
まず,平常時(例:14:29〜14:42)のログ件数から平均を求めます.
| 時刻 | 件数 |
|---|---|
| 14:29〜14:42 | 47, 55, 54, 54, 54, 54, 53, 52, 54, 54, 54, 54, 54, 53 |
計算式: λ₀ = (合計) / (データ数) λ₀ = 750 / 14 = 53.6
したがって,平常状態の平均発生率は λ₀ = 53.6 件/分 です.
2. 有意水準(α)を決める¶
異常を「どのくらい珍しいときに検出するか」を決めます.
この値を 有意水準(α) といいます.
| α | 意味 | 備考 |
|---|---|---|
| 0.05 | 20回に1回起こる | 緩い基準 |
| 0.01 | 100回に1回起こる | 一般的 |
| 0.001 | 1000回に1回起こる | 監視用途に適する(誤報が少ない) |
今回は α = 0.001(1000回に1回)を採用します.
→要は,正常と判断できる値の範囲(この値からこの値まではOKとする)を決めます.
3. ポアソン分布の上側確率¶
ポアソン分布では,「$x$ 件以上が起きる確率」は次の式で表されます.
P(X ≥ x) = 1 - F(x - 1; λ₀)
ここで $F(k; λ₀)$ は,ポアソン分布の累積分布関数(CDF)です.難しいので覚えなくていいです. この確率が有意水準よりも小さくなったとき, その値 $x$ を「しきい値」(比較基準となる値)とします.
→要は,異常かどうかを判断する基準の値(範囲の最大)を決めるということです.
4. しきい値の定義¶
次の条件を満たす最小の整数 $x_t$ をしきい値とします.
P(X ≥ x_t | λ₀) ≤ α
つまり,
平常時の平均 λ₀ のもとで,
$x_t$ 件以上になる確率が 0.001 以下になる点
を求めます.
5. 実際に求めてみる(λ₀ = 53.6, α = 0.001)¶
$P(X ≥ x)$ を順に計算していくと,次のようになります.
| $x$(件数) | $P(X ≥ x)$ | 判定 |
|---|---|---|
| 70 | 0.022 | まだ起きやすい |
| 75 | 0.0047 | まだ少し高い |
| 78 | 0.0015 | ほぼ基準 |
| 79 | 0.0009 | α=0.001を下回る! |
| 80 | 0.0006 | より珍しい |
したがって,しきい値 xₜ = 79です.
6. しきい値の意味¶
| 状況 | 件数 | 判定 |
|---|---|---|
| 60件/分 | よくある範囲(p ≈ 0.05) | |
| 75件/分 | 少し多いがまだ偶然ありうる(p ≈ 0.004) | |
| 79件以上/分 | 1000回に1回以下 → 異常(バースト) |
つまり,
「1分あたりのログ件数が79件を超えたら,
その現象は偶然ではなく“異常”の可能性が高い」
と判断できます.
7. 実データへの適用例¶
| 時刻 | 件数 | 判定 |
|---|---|---|
| 14:42 | 53 | 正常 |
| 14:43 | 94 | 異常(94 > 79) |
| 14:44〜14:59 | 約150件 | 異常継続 |
→ 14:43 から異常が始まったことがわかります.
なぜこの方法がよいのか¶
- 平均値を自動で計算するので,しきい値を手で決めなくてよい
- データのばらつきを考慮して「本当に珍しい」かどうかを判断できる
- 計算が簡単で,Pythonなどで簡単に実装できる