こんにちは,修士2年の平尾真斗です!この記事は,「1.Kubernetes上のPodでGPUを使えるようにした話(ハードウェア編)」の続きです.読んでいない人はぜひ読んでみてくださいね!Kubernetes上のPodをGPUを使えるようにするソフトウェアの構成を説明します.ブログの構成はハードウェア編,ソフトウェア編→Ubuntu上,ソフトウェア編→Kubernetes上の3つに分けて書きます.この記事はソフトウェア編→Ubuntu上です.
記事一覧⇩
https://ja.tak-cslab.org/archives/7931
https://ja.tak-cslab.org/archives/7957→今回の記事
https://ja.tak-cslab.org/archives/7960
GPUをPodで使用できるようにするための構成は以下になります.いろいろ載っているんですけど説明します.
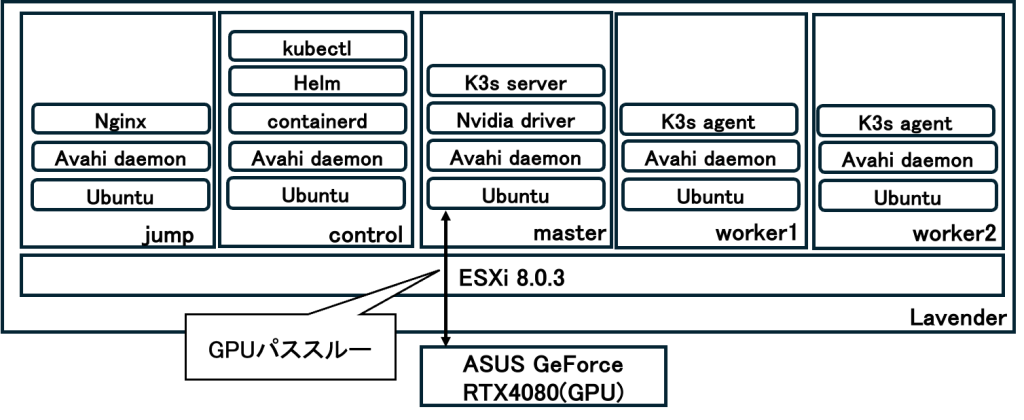
Lavender には ESXi 8.0.3 をインストールしました.ESXi 上には 5 台の仮想マシンを構築し,それぞれに Ubuntu をインストールしています.
- jump
- 踏み台サーバおよびリバースプロキシとして機能します.Ubuntu 上には Nginx と Avahi daemon をインストールしています.
- control
- kubectl コマンドを Kube API Server に送信する管理ノードの役割を担います.また,コンテナのビルドやイメージ作成,レジストリへの Push を行うサーバでもあります.Ubuntu 上には,Avahi daemon,containerd,Helm,kubectl をインストールしています.
- master
- GPU を Kubernetes の Pod から利用するためのノードです.Ubuntu 上には,Avahi daemon,NVIDIA Driver,K3s Server をインストールしています.Kubernetes クラスタは master,worker1,worker2 の 3 台で構成されていますが,GPU を利用した Pod を実行できるのは master のみです.1台だけしか使えない理由は後で説明します.
- worker1 とworker2
- Kubernetes クラスタのワーカーノードです.Ubuntu 上には,Avahi daemon と K3s Agent をインストールしています.
GPUを使用するためにやったこと
GPUパススルー
GPUパススルーとは,物理GPUを仮想マシンに直接割り当て,仮想マシンからGPUを利用できるようにする技術です.GPUパススルーを行う手法は2つあります.
- vDGA
- 仮想マシン1台に対してGPUを割り振る方式
- vGPU
- 複数の仮想マシンにGPUを割り振る方式
今回は,vDGA によって仮想マシン 1 台に GPU を直接割り当てる方式を採用しました.本当は, vGPU を利用し,1 枚の GPU を複数の仮想マシンで共有したかったのですが,vGPU に対応している GPU は限られています.公開されている対応表を確認したところ,今回使用した GPU は vGPU に対応していないことが分かりました.どうやら,vGPU は主にデータセンター向けの GPU が対象となっているようです.→これちゃんと確認してからGPUを買った方がいいです!
vDGAを行うにあたって行ったことは,ESXi上でのPCIデバイスの認識とPCIデバイスを仮想マシン側で認識させる作業です.GPUを配置した状態でハイパーバイザのUI上の「管理」から「PCIデバイス」から簡単に有効化できます.
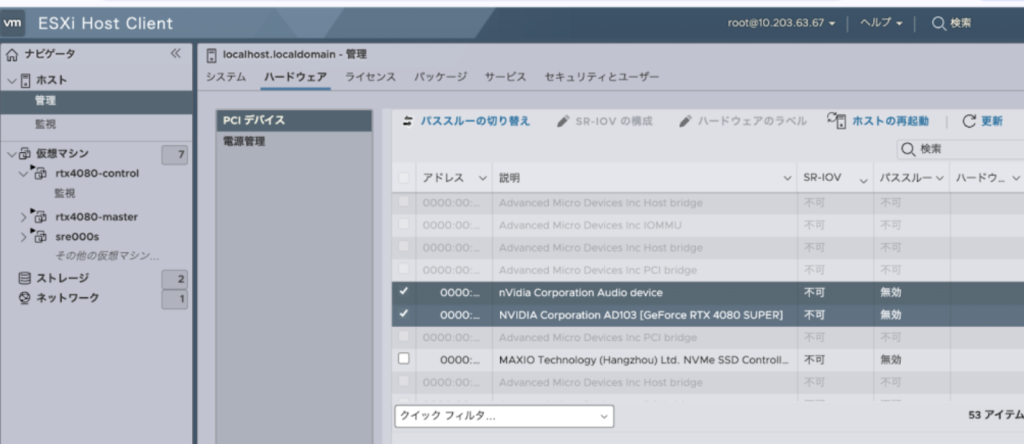
仮想マシンからPCIデバイスを認識させる作業は「その他のデバイスの追加」からPCIデバイスを追加して認識させればOKです.
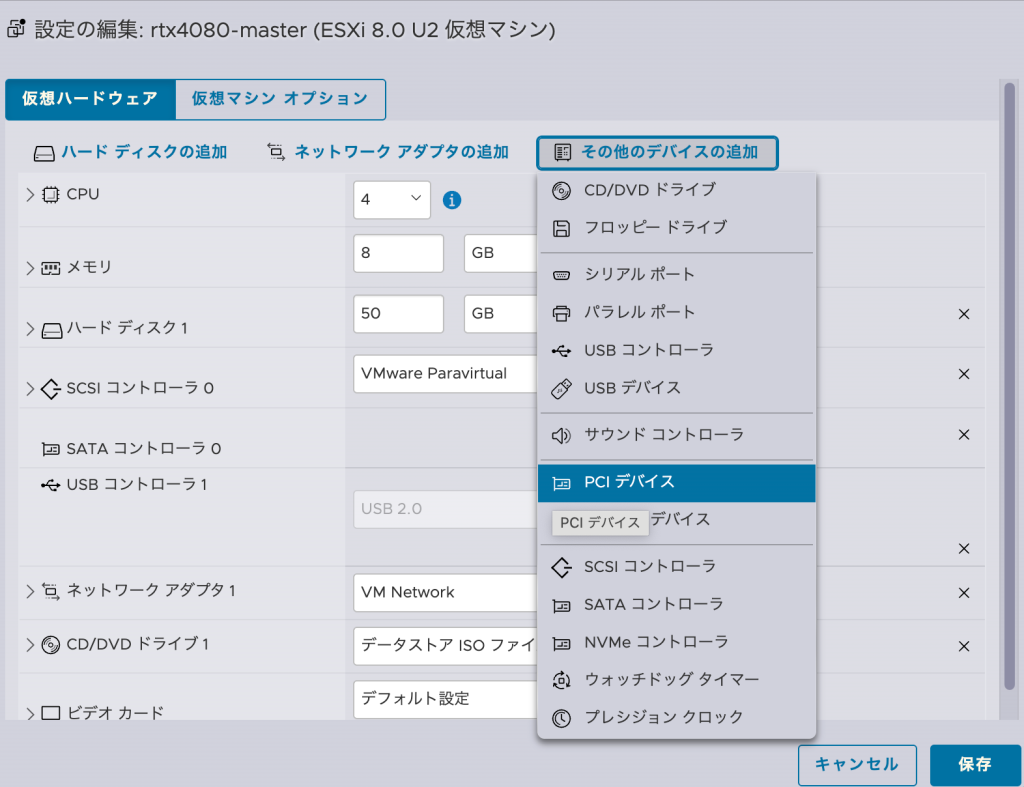
仮想マシンの設定でPCIデバイスを選択すればOKです.
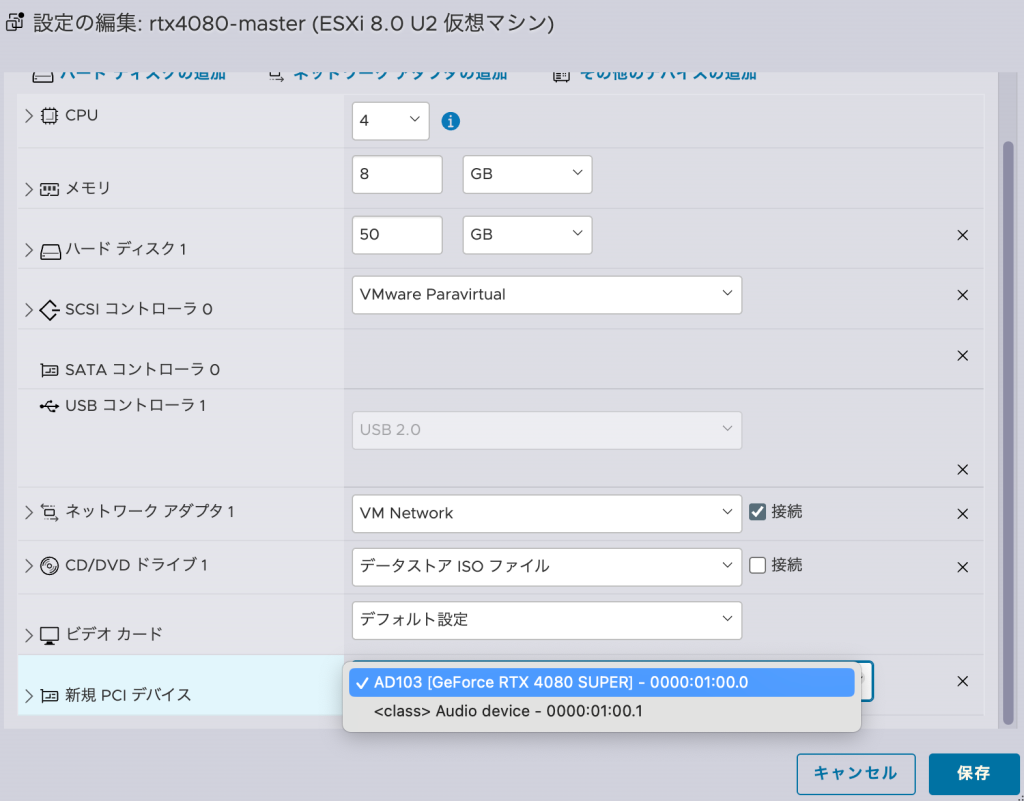
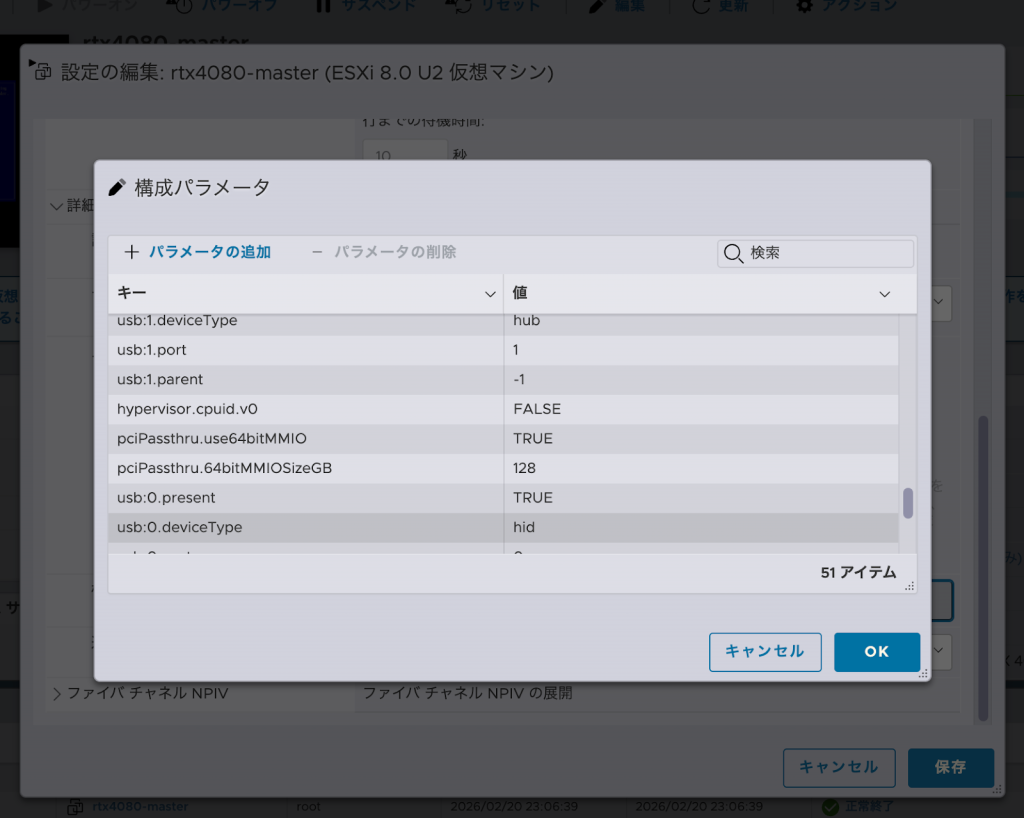
あとは,仮想マシンの「構成パラメータ」から以下の箇所を追加すれば起動することができます.この記事が参考になったのでぜひ使ってみてください.
- pciPassthru.use64bitMMIO=“TRUE”
- PCI パススルーしたデバイスに対して64bitのMMIO(Memory Mapped I/O)領域を使用するかどうかを指定する設定です.TRUE に設定することで,4GB を超えるアドレス空間を利用できるようになり,大容量のメモリ領域を必要とするデバイス(主に GPU)を正しく認識できるようになります.
- pciPassthru.64bitMMIOSizeGB=“128”
- pciPassthru.64bitMMIOSizeGB=”128″ は,64bit MMIO 領域として仮想マシンに割り当てるアドレス空間のサイズを GB 単位で指定する設定です.この例では,GPU 用に 128GB 分の MMIO 空間を確保することを意味します.大容量の VRAM を持つ GPU をパススルーする場合に必要となります.
あとは起動してGPUが認識されている確認してNVIDIA Corporation AD103 [GeForce RTX 4080 SUPER] (rev a1)が出ればOKです.
hirao@rtx4080-master:~$ lspci | grep -i vga
00:0f.0 VGA compatible controller: VMware SVGA II Adapter
02:02.0 VGA compatible controller: NVIDIA Corporation AD103 [GeForce RTX 4080 SUPER] (rev a1)
hirao@rtx4080-master:~$
Nvidia GPUドライバのインストール
NvidiaのGPUを使えるようにするためには,Ubuntu上にドライバをインストールする必要がありました.確認すると最新版は,nvidia-driver-590-openだったのでそれをインストールしました.
hirao@rtx4080-master:~$ sudo apt install nvidia-driver-590-open -y
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
・・・長いので省略
hirao@rtx4080-master:~$nvidia-smiと入力するとGPUの使用状況とか見れるので確認してみてください!
hirao@rtx4080-master:~$ nvidia-smi
Fri Feb 20 07:03:58 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4080 ... Off | 00000000:02:02.0 Off | N/A |
| 0% 28C P8 5W / 320W | 1MiB / 16376MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
hirao@rtx4080-master:~$ Kubernetesクラスタの作成
master
Podを配置するためのK3sを用いたクラスタの作成をします.master側は,curl -sfL https://get.k3s.io | sh -を入力するだけで簡単にできます.
hirao@rtx4080-master:~$ curl -sfL https://get.k3s.io | sh -
[INFO] Finding release for channel stable
[INFO] Using v1.34.4+k3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.34.4+k3s1/sha256sum-amd64.txt
[INFO] Downloading binary https://github.com/k3s-io/k3s/releases/download/v1.34.4+k3s1/k3s
[INFO] Verifying binary download
[INFO] Installing k3s to /usr/local/bin/k3s
[INFO] Skipping installation of SELinux RPM
[INFO] Creating /usr/local/bin/kubectl symlink to k3s
[INFO] Creating /usr/local/bin/crictl symlink to k3s
[INFO] Creating /usr/local/bin/ctr symlink to k3s
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
hirao@rtx4080-master:~$ worker
Worker側は,SSHで接続したらMasterのホスト名かIPアドレスを入れてトークンをしたのコマンドに含めて実行させればOKです.
トークンの取り方は/var/lib/rancher/k3s/server/node-tokenをcatで見ればわかります.
hirao@rtx4080-master:~$ sudo cat /var/lib/rancher/k3s/server/node-token
<ここにトークンが出てくる>
hirao@rtx4080-master:~$ K3sのワーカのインストール
hirao@rtx4080-worker1:~$ curl -sfL https://get.k3s.io | \
K3S_URL=https:<Masterのホスト名 OR IPアドレス> \
K3S_TOKEN=<Token> \
sh -
[INFO] Finding release for channel stable
[INFO] Using v1.34.4+k3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.34.4+k3s1/sha256sum-amd64.txt
[INFO] Downloading binary https://github.com/k3s-io/k3s/releases/download/v1.34.4+k3s1/k3s
[INFO] Verifying binary download
[INFO] Installing k3s to /usr/local/bin/k3s
[INFO] Skipping installation of SELinux RPM
[INFO] Creating /usr/local/bin/kubectl symlink to k3s
[INFO] Creating /usr/local/bin/crictl symlink to k3s
[INFO] Creating /usr/local/bin/ctr symlink to k3s
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-agent-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s-agent.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s-agent.service
[INFO] systemd: Enabling k3s-agent unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s-agent.service → /etc/systemd/system/k3s-agent.service.
[INFO] systemd: Starting k3s-agent
hirao@rtx4080-worker1:~$K3sのMasterでkubectl get nodeを打ちます.3つのNodeがReadyになればOKです.
hirao@rtx4080-master:~$ sudo kubectl get node
NAME STATUS ROLES AGE VERSION
rtx4080-master Ready control-plane 7m4s v1.34.4+k3s1
rtx4080-worker1 Ready <none> 97s v1.34.4+k3s1
rtx4080-worker2 Ready <none> 39s v1.34.4+k3s1
hirao@rtx4080-master:~$ 最後に
GPUを使ったサーバのソフトウェアは,初めて触ったのでなかなか新鮮でした.次はKubernrtes上でGPUを使用するための設定をします.その記事は,次に載せるのでたのしみにしててください!